
How to Reduce Unplanned Downtime in Manufacturing
To reduce unplanned downtime in manufacturing, leaders usually need more than better maintenance. They need better visibility across plant operations, clearer escalation paths, faster IT and OT recovery, stronger cyber resilience, and tighter coordination between operations, maintenance, and technology teams. The goal is not perfect uptime. It is fewer disruptions, faster recovery, and fewer repeat failures.
For most manufacturers, downtime starts before the line fully stops. Slowness, delayed alerts, weak handoffs, access problems, and unclear ownership often create more lost time than the final stoppage itself. That broader view also aligns with the NIST Cybersecurity Framework 2.0, which treats resilience as a mix of identification, protection, detection, response, recovery, and continuous improvement rather than prevention alone.
Executive summary
- Downtime often begins with small failures in visibility, communication, or response.
- Hidden causes commonly include technology dependencies, delayed escalation, poor restart discipline, and slow vendor coordination.
- A strong manufacturing uptime strategy focuses on prevention, faster detection, faster recovery, and clearer accountability.
That broader view matters for executives responsible for output, labor efficiency, customer commitments, and operational credibility. It also explains why many organizations exploring manufacturing IT services are not looking for another vendor relationship. They are looking for clearer control over disruption risk and a better handle on the cost of IT downtime when plant systems, support processes, or coordination gaps slow recovery.
What unplanned downtime in manufacturing really includes
Unplanned downtime in manufacturing is not limited to a machine that suddenly fails. It includes any unplanned interruption that slows, stops, or complicates production.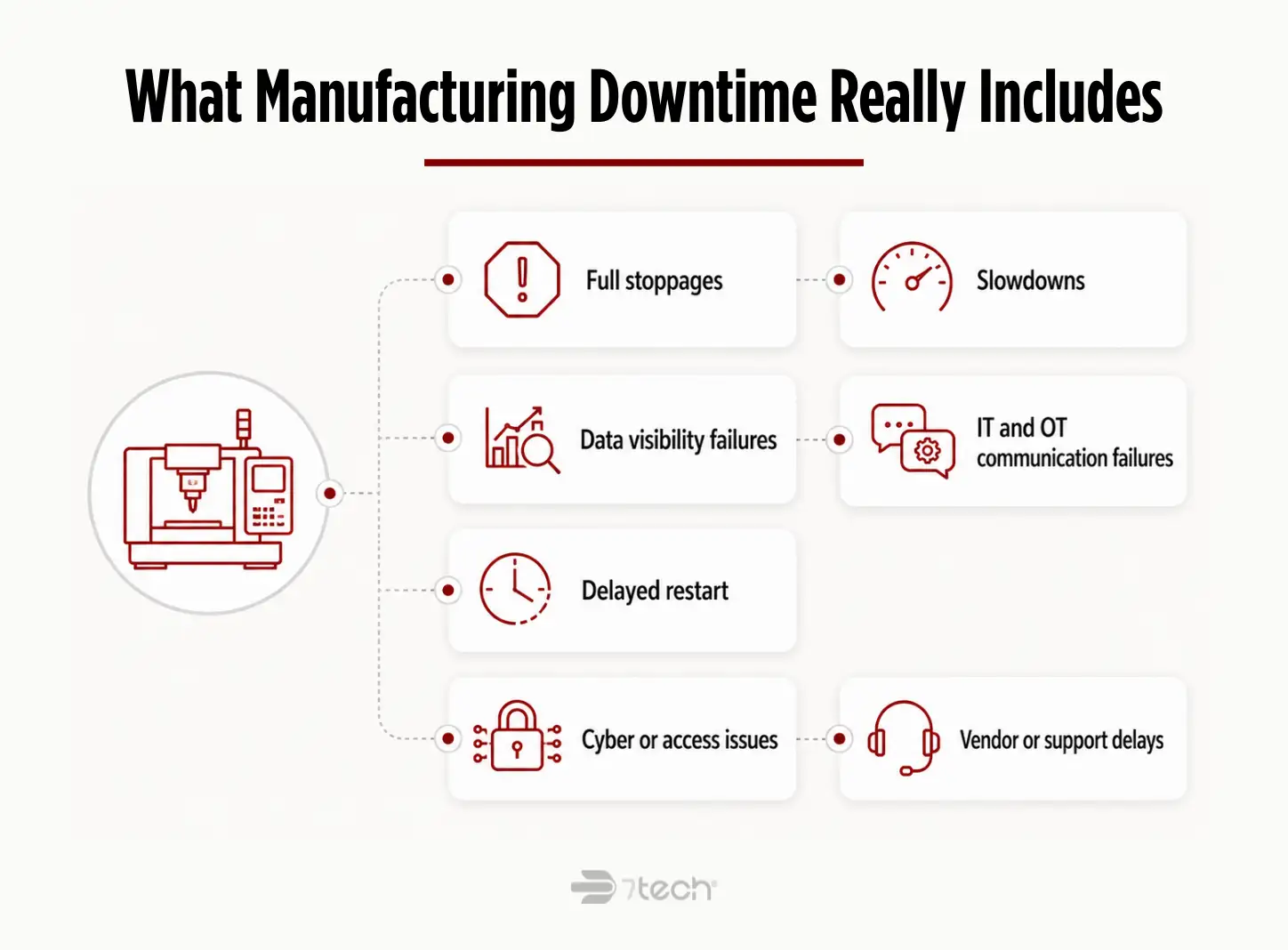
- Full production stoppages
- Slowdowns and recurring micro-disruptions
- Data visibility failures that delay decisions
- OT and IT communication failures
- Delayed restart after a stoppage
- Cyber or access issues that interrupt plant activity
- Vendor or support delays that extend the disruption
That is why plant uptime should be treated as an operations issue with maintenance, IT, OT, leadership, and outside support all affecting the final outcome. Public guidance such as CISA industrial control systems best practices reinforces this point by tying plant resilience to visibility, access control, segmentation, and response discipline, not just physical equipment reliability.
The hidden causes of unplanned downtime leaders tend to underestimate
The most expensive downtime causes are often the least visible in a standard maintenance review. Leaders tend to underestimate the time lost between the first sign of trouble and a coordinated response.
- Fragmented visibility between plant, IT, and operations teams
- Weak escalation procedures
- Slow troubleshooting handoffs
- Poor network resilience or fragile system dependencies
- Inaccurate or delayed production data
- Unclear ownership during incidents
- Cybersecurity events that interrupt operations
- Recovery processes that exist on paper but are not tested in practice
In many plants, no single team is doing anything wrong. The problem is that the downtime chain crosses too many boundaries. A sensor alert, a user access issue, an ERP lag, a network interruption, or an external support delay can all land in different queues with no unified view of business impact.
That is one reason manufacturers often need stronger managed security services and operational oversight at the same time. Cyber and uptime are related, but neither should swallow the other. A plant can lose valuable time from a security event, a permissions problem, or a defensive control that no one is ready to manage quickly. In some environments, that also means making sure teams can secure OT and plant operations without turning OT security into a separate conversation from uptime.
Where manufacturers lose time before the line officially stops
Executives often notice downtime only after production has clearly stopped. In practice, a surprising amount of lost time shows up earlier.
- Recurring slowness that operators learn to work around
- Intermittent connectivity problems between systems and devices
- Lag between ERP, MES, plant-floor devices, and end users
- Repeated manual workarounds that hide the true issue
- Operator uncertainty about what failed and who owns it
- Waiting on an outside vendor to begin triage
- Delayed incident recognition because no one has full visibility
This is where many downtime reduction plans stall. The organization reviews the stoppage, but not the chain of friction that made the issue harder to detect, escalate, and recover from.
If this sounds familiar, it often helps to examine narrow causes separately. For example, manufacturers dealing with recurring connectivity or availability problems may benefit from a deeper look at downtime caused by IT and network issues. Likewise, recurring data mismatches between business systems and the floor can point to broader visibility gaps, which is why many leaders eventually ask why ERP data does not match the shop floor.
How IT, OT, maintenance, and support all affect uptime
Maintenance owns physical reliability, but it does not own the entire downtime problem.
IT affects connectivity, systems availability, backup access, user support, authentication, reporting, vendor coordination, and incident communication. OT security and access controls affect plant continuity. Operations leadership affects escalation speed, shift accountability, and decision-making under pressure. Outside partners can either shorten recovery time or extend it.
A strong response model respects each function without blaming any one of them. Technical leaders should feel supported, not second-guessed. Operational leaders should have enough clarity to make decisions quickly. Executives should be able to see where delays occur without turning every incident into a postmortem on one department.
That cross-functional posture also aligns with manufacturing-specific resilience guidance such as CISA guidance for the critical manufacturing sector, which emphasizes defined responsibilities, communication discipline, supplier coordination, and tested response and recovery processes.
How to build a downtime reduction plan that holds up
The most useful plant downtime reduction plan is practical, repeatable, and owned across functions. It should reduce avoidable disruption before, during, and after an incident.
Map the full downtime chain
Start with the full sequence, not just the visible outage. Where do disruptions begin? Who notices them first? Who gets involved next? What usually slows recovery?
Map the real chain from first symptom to stable restart. Many manufacturers discover that the biggest delays happen during recognition, triage, approval, or vendor coordination rather than during the technical fix itself.
Identify the biggest non-obvious downtime drivers
Focus first on recurring and preventable delays rather than rare catastrophic events. Look for patterns such as repeated authentication failures, unstable remote access, recurring system lag, inconsistent alerts, or a support model that depends too heavily on one person.
This is also the right place to review whether your current mix of tools and providers creates friction instead of clarity. For some organizations, broader IT solutions that reduce downtime come from simplifying support paths, alerting, and recovery workflows rather than adding more software.
Clarify ownership during an incident
Every incident should answer four questions quickly:
- Who leads the response
- Who escalates and to whom
- Who communicates with affected stakeholders
- Who verifies that production is actually stable again
If those answers are unclear during a live event, downtime expands. Clear roles reduce decision lag and help leadership avoid confusion when multiple teams and vendors are involved.
Strengthen recovery readiness
Many organizations spend more time planning prevention than recovery. Both matter.
- Confirm backup and restoration readiness
- Document access restoration steps
- Check device readiness and spare-process assumptions
- Maintain practical runbooks, not shelf documents
- Keep vendor contacts and escalation paths current
The target is not a perfect environment. It is a faster, calmer recovery process when something goes wrong.
Cyber-related interruptions are only one downtime category, but they still matter. If recovery planning does not account for that risk, manufacturers may also need to consider how they can protect a manufacturing plant from ransomware while keeping the broader uptime strategy focused on operations as a whole.
Reduce dependence on one person or one vendor
Single points of knowledge are common in manufacturing incident response. If one internal expert, one outside provider, or one plant leader becomes the bottleneck, recovery slows.
Reduce fragility by documenting critical steps, cross-training where possible, and making sure key vendors can be reached and understood quickly. If your team is evaluating provider support quality, this is also a good point to review questions to ask your IT provider around response, communication, escalation, and accountability.
Review systems that create friction between plant and business operations
Manufacturing uptime depends on more than the plant floor. Review the systems that create friction across the operation:
- ERP and production data flows
- Connectivity and remote access
- Authentication and account recovery
- Reporting and alert quality
- Support workflows across shifts and sites
These systems rarely make headlines in a downtime review, but they often determine whether a minor issue stays minor.
Which metrics show whether downtime is actually improving
Executives do not need an engineering dashboard full of noise. They need a short set of measures that show whether operations are becoming more resilient and recovery is getting faster.
For executives, these measures are often more useful than a long list of technical counters. They make it easier to judge whether support processes, reporting, and operational discipline are getting stronger. If you need a broader framework for board-ready visibility, it can also help to review how to evaluate IT performance.
When outside support can help reduce unplanned downtime faster
Outside support becomes especially valuable when internal teams are overloaded, visibility is fragmented across sites and vendors, or downtime causes cross into IT, OT, security, and compliance at the same time.
It can also help when recovery depends too heavily on one internal expert, when reporting is inconsistent, or when leadership wants clearer accountability without adding more management overhead.
The right outside support model should reduce noise, improve response coordination, and strengthen recovery readiness. It should not make internal teams feel displaced or blamed. The best partnerships give leadership clearer insight, give technical teams better support, and give operations a more dependable path through incidents.
FAQ
What is unplanned downtime in manufacturing?
Unplanned downtime in manufacturing is any unexpected interruption that slows, stops, or complicates production. It includes full stoppages, recurring slowdowns, data failures, access problems, and delayed restarts.
What are the most common hidden causes of manufacturing downtime?
Common hidden causes include fragmented visibility, weak escalation, slow handoffs, unstable connectivity, delayed data, unclear ownership, vendor delays, and recovery processes that are documented but not practiced.
How does IT affect unplanned downtime in a plant?
IT affects uptime through connectivity, authentication, backups, reporting, user support, system availability, remote access, and coordination with outside providers. A technology issue can extend plant disruption even when equipment is operational.
What metrics help measure downtime improvement?
Useful measures include incident frequency, mean time to detect, mean time to respond, mean time to recover, repeat incident rate, time lost before escalation, the percentage of incidents with documented root cause follow-up, and production-impact trends tied to technology-related causes.
How can manufacturers reduce recovery time after an incident?
They can shorten recovery by clarifying roles, testing backups and access restoration, keeping runbooks current, validating vendor contacts, and reducing dependence on one person or one provider.
What is the difference between a maintenance problem and a downtime management problem?
A maintenance problem is about physical asset reliability. A downtime management problem is broader. It includes detection, escalation, communication, technology dependencies, restart discipline, and cross-functional recovery.
When should a manufacturer bring in outside IT or cybersecurity support?
Outside support is often helpful when internal teams are stretched thin, multiple vendors slow response, visibility is fragmented, cyber risk affects operations, or leadership needs clearer reporting and stronger incident accountability.
What Leadership Should Prioritize to Reduce Downtime
Manufacturers reduce unplanned downtime when they stop treating it as a single-team problem. The fastest gains usually come from better visibility, faster escalation, stronger recovery discipline, and clearer accountability across operations, maintenance, IT, and OT.
That approach is more realistic than chasing the idea of perfect uptime. It helps leaders reduce avoidable disruption, recover faster when issues occur, and make better decisions about where support, process changes, and technology improvements will have the most operational value.
Schedule a Clarity and Control Consultation
If you want a clearer view of manufacturing uptime risk, downtime exposure, and the process gaps that may be extending recovery, schedule a Clarity and Control Consultation. It is a practical next step for leadership teams that want fewer surprises, stronger accountability, and a more defensible uptime strategy.

Neal Juern, Founder and CEO of 7tech, helps business leaders take control of their IT and strengthen cybersecurity without the complexity. Since founding 7tech in 2012, he’s built it into a 5X MSP 501 winner and guided hundreds of executives toward smarter, safer operations through Managed IT Services and Managed Security Services that make sense to people outside the IT department. He speaks regularly to executive and nonprofit audiences across Texas.






